PgSQL · 实战经验 · 如何预测Freeze IO风暴
本文共 6739 字,大约阅读时间需要 22 分钟。

背景和原理
有没有被突发的IO惊到过,有没有见到过大量的autovacuum for prevent wrap。
PostgreSQL 的版本冻结是一个比较蛋疼的事情,为什么要做版本冻结呢? 因为PG的版本号是uint32的,是重复使用的,所以每隔大约20亿个事务后,必须要冻结,否则记录会变成未来的,对当前事务”不可见”。 冻结的事务号是2src/include/access/transam.h#define InvalidTransactionId ((TransactionId) 0)#define BootstrapTransactionId ((TransactionId) 1)#define FrozenTransactionId ((TransactionId) 2)#define FirstNormalTransactionId ((TransactionId) 3)#define MaxTransactionId ((TransactionId) 0xFFFFFFFF)
现在,还可以通过行的t_infomask来区分行是否为冻结行
src/include/access/htup_details.h/* * information stored in t_infomask: */#define HEAP_XMIN_COMMITTED 0x0100 /* t_xmin committed */#define HEAP_XMIN_INVALID 0x0200 /* t_xmin invalid/aborted */#define HEAP_XMIN_FROZEN (HEAP_XMIN_COMMITTED|HEAP_XMIN_INVALID)
表的最老事务号则是记录在pg_class.relfrozenxid里面的。
执行vacuum freeze table,除了修改t_infomask,还需要修改该表对应的pg_class.relfrozenxid的值。
那么系统什么时候会触发对表进行冻结呢?
当表的年龄大于autovacuum_freeze_max_age时(默认是2亿),autovacuum进程会自动对表进行freeze。
freeze后,还可以清除掉比整个集群的最老事务号早的clog文件。 那么可能会出现这样的情形: 可能有很多大表的年龄会先后到达2亿,数据库的autovacuum会开始对这些表依次进行vacuum freeze,从而集中式的爆发大量的读IO(DATAFILE)和写IO(DATAFILE以及XLOG)。 如果又碰上业务高峰,会出现很不好的影响。为什么集中爆发Freeze很常见?
因为默认情况下,所有表的autovacuum_freeze_max_age是一样的,并且大多数的业务,一个事务或者相邻的事务都会涉及多个表的操作,所以这些大表的最老的事务号可能都是相差不大的。 这样,就有非常大的概率导致很多表的年龄是相仿的,从而导致集中的爆发多表的autovacuum freeze。PostgreSQL有什么机制能尽量的减少多个表的年龄相仿吗?
目前来看,有一个机制,也许能降低年龄相仿性,但是要求表有发生UPDATE,对于只有INSERT的表无效。 vacuum_freeze_min_age 这个参数,当发生vacuum或者autovacuum时,扫过的记录,只要年龄大于它,就会置为freeze。因此有一定的概率可以促使频繁更新的表年龄不一致。那么还有什么手段能放在或者尽量避免大表的年龄相仿呢?
为每个表设置不同的autovacuum_freeze_max_age值,从认为的错开来进行vacuum freeze的时机。 例如有10个大表,把全局的autovacuum_freeze_max_age设置为5亿,然后针对这些表,从2亿开始每个表间隔1000万事务设置autovacuum_freeze_max_age。 如2亿,2.1亿,2.2亿,2.3亿,2.4亿….2.9亿。 除非这些表同时达到 2亿,2.1亿,2.2亿,2.3亿,2.4亿….2.9亿。 否则不会出现同时需要vacuum freeze的情况。但是,如果有很多大表,这样做可能就不太合适了。
建议还是人为的在业务空闲时间,对大表进行vacuum freeze。优化建议
1. 分区,把大表分成小表。每个表的数据量取决于系统的IO能力,前面说了VACUUM FREEZE是扫全表的, 现代的硬件每个表建议不超过32GB。 2. 对大表设置不同的vacuum年龄. alter table t set (autovacuum_freeze_max_age=xxxx); 3. 用户自己调度 freeze,如在业务低谷的时间窗口,对年龄较大,数据量较大的表进行vacuum freeze。 4. 年龄只能降到系统存在的最早的长事务即 min pg_stat_activity.(backend_xid, backend_xmin)。 因此也需要密切关注长事务。讲完了Freeze的背景,接下来给大家讲讲如何预测Freeze IO风暴。
预测 IO 风暴
如何预测此类(prevent wrapped vacuum freeze) IO 风暴的来临呢?
首先需要测量几个维度的值。- 表的大小以及距离它需要被强制vacuum freeze prevent wrap的年龄
- 每隔一段时间的XID值的采样(例如每分钟一次),采样越多越好,因为需要用于预测下一个时间窗口的XID。(其实就是每分钟消耗多少个事务号的数据)
- 通过第二步得到的结果,预测下一个时间窗口的每分钟的pXID(可以使用线性回归来进行预测) 预测方法这里不在细说,也可以参考我以前写的一些预测类的文章。
预测的结论包括”未来一段时间的总Freeze IO量,以及分时的Freeze IO量”。
预测结果范例 Freeze IO 时段总量 Freeze IO 分时走势
Freeze IO 分时走势 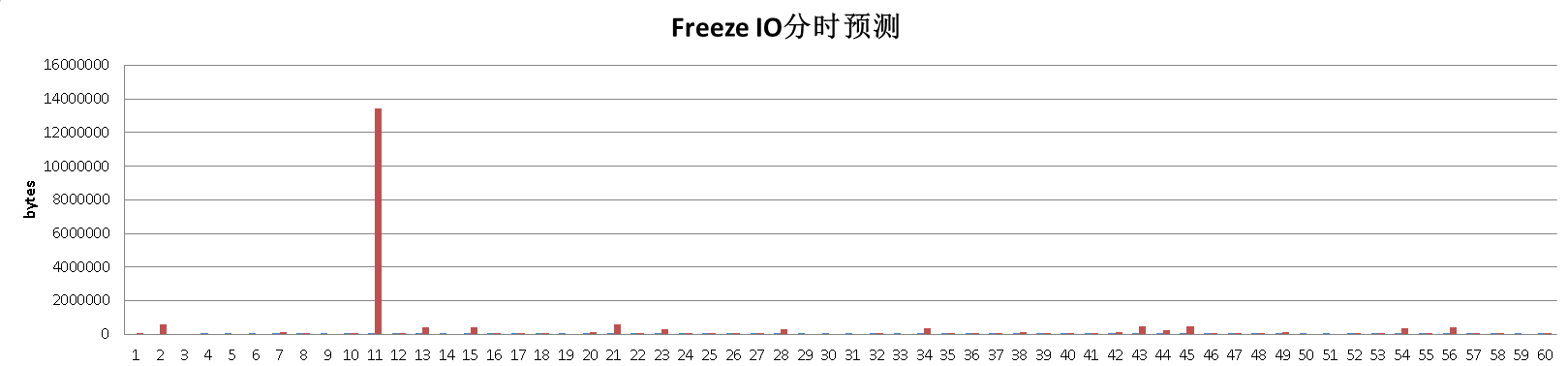
预测过程
- 每隔一段时间的XID值的采样(例如每分钟一次),采样越多越好,因为需要用于预测下一个时间窗口的XID。(其实就是每分钟消耗多少个事务号的数据)
vi xids.sh#!/bin/bashexport PATH=/home/digoal/pgsql9.5/bin:$PATHexport PGHOST=127.0.0.1export PGPORT=1921export PGDATABASE=postgresexport PGUSER=postgresexport PGPASSWORD=postgrespsql -c "create table xids(crt_time timestamp, xids int8)"for ((i=1;i>0;))do# 保留1个月的数据psql -c "with a as (select ctid from xids order by crt_time desc limit 100 offset 43200) delete from xids where ctid in (select ctid from a);"psql -c "insert into xids values (now(), txid_current());"sleep 60donechmod 500 xids.shnohup ./xids.sh >/dev/null 2>&1 &
采集1天的数据可能是这样的
postgres=# select * from xids ; crt_time | xids ----------------------------+------ 2016-06-12 12:36:13.201315 | 2020 2016-06-12 12:37:13.216002 | 9021 2016-06-12 12:38:13.240739 | 21022 2016-06-12 12:39:13.259203 | 32023 2016-06-12 12:40:13.300604 | 42024 2016-06-12 12:41:13.325874 | 52025 2016-06-12 12:42:13.361152 | 62026 2016-06-12 12:43:15.481609 | 72027...
- 表的大小以及距离它需要被强制vacuum freeze prevent wrap的年龄(因为freeze是全集群的,所以需要把所有库得到的数据汇总到一起)
vi pred_io.sh#!/bin/bashexport PATH=/home/digoal/pgsql9.5/bin:$PATHexport PGHOST=127.0.0.1export PGPORT=1921export PGDATABASE=postgresexport PGUSER=postgresexport PGPASSWORD=postgrespsql -c "drop table pred_io; create table pred_io(crt_time timestamp, bytes int8, left_live int8);"for db in `psql -A -t -q -c "select datname from pg_database where datname <> 'template0'"`dopsql -d $db -c " copy (select now(), bytes, case when max_age>age then max_age-age else 0 end as xids from (select block_size*relpages bytes, case when d_max_age is not null and d_max_age
得到的数据可能是这样的
postgres=# select * from pred_io limit 10; crt_time | bytes | left_live ----------------------------+--------+----------- 2016-06-12 13:24:08.666995 | 131072 | 199999672 2016-06-12 13:24:08.666995 | 65536 | 199999672 2016-06-12 13:24:08.666995 | 0 | 199999672 2016-06-12 13:24:08.666995 | 0 | 199999672 2016-06-12 13:24:08.666995 | 0 | 199999672 2016-06-12 13:24:08.666995 | 0 | 199999672...
- 预测XIDs走势(略),本文直接取昨天的同一时间点开始后的数据。
create view v_pred_xids as with b as (select min(crt_time) tbase from pred_io), a as (select crt_time + interval '1 day' as crt_time, xids from xids,b where crt_time >= b.tbase - interval '1 day') select crt_time, xids - (select min(xids) from a) as xids from a ;
数据可能是这样的,预测未来分时的相对XIDs消耗量
crt_time | xids ----------------------------+------ 2016-06-13 12:36:13.201315 | 0 2016-06-13 12:37:13.216002 | 100 2016-06-13 12:38:13.240739 | 200 2016-06-13 12:39:13.259203 | 300 2016-06-13 12:40:13.300604 | 400
- 结合pred_io与v_pred_xids 进行 io风暴预测 基准视图,后面的数据通过这个基准视图得到
create view pred_tbased_io aswith a as (select crt_time, xids as s_xids, lead(xids) over(order by crt_time) as e_xids from v_pred_xids)select a.crt_time, sum(b.bytes) bytes from a, pred_io b where b.left_live >=a.s_xids and b.left_live < a.e_xids group by a.crt_time order by a.crt_time;
未来一天的总freeze io bytes预测
postgres=# select min(crt_time),max(crt_time),sum(bytes) from pred_tbased_io ; min | max | sum ----------------------------+----------------------------+---------- 2016-06-13 12:36:13.201315 | 2016-06-14 12:35:26.104025 | 19685376(1 row)
未来一天的freeze io bytes分时走势
得到的结果可能是这样的postgres=# select * from pred_tbased_io ; crt_time | bytes ----------------------------+---------- 2016-06-13 12:36:13.201315 | 65536 2016-06-13 12:37:13.216002 | 581632 2016-06-13 12:38:13.240739 | 0 2016-06-13 12:39:13.259203 | 0 2016-06-13 12:40:13.300604 | 0 2016-06-13 12:41:13.325874 | 0 2016-06-13 12:43:15.481609 | 106496 2016-06-13 12:43:24.133055 | 8192 2016-06-13 12:45:24.193318 | 0 2016-06-13 12:46:24.225559 | 16384 2016-06-13 12:48:24.296223 | 13434880 2016-06-13 12:49:24.325652 | 24576 2016-06-13 12:50:24.367232 | 401408 2016-06-13 12:51:24.426199 | 0 2016-06-13 12:52:24.457375 | 393216......
小结
预测主要用到哪些PostgreSQL的手段?
- 线性回归
- with语法
- 窗口函数
- xid分时消耗统计
- 强制prevent wrap freeze vacuum的剩余XIDs统计
转载地址:http://ouxyo.baihongyu.com/
你可能感兴趣的文章
Date15
查看>>
从Date类型转为中文字符串
查看>>
el-popover可以设高度_农村建房资金充裕,不妨建个地下室,车库、酒窖、卡拉OK都可以...
查看>>
基于multisim的fm调制解调_苹果开始自研蜂窝网调制解调器 最快2024年能用上?
查看>>
mupdf不支持x64_Window权限维持(七):安全支持提供者
查看>>
cf修改游戏客户端是什么意思_瓦罗兰特很有可能取代cf成为国内最火的fps游戏...
查看>>
proto文件支持继承吗_JavaScript继承(一)——原型链
查看>>
labview如何弹出提示窗口_LabVIEW开发者必读的问答汇总,搞定疑难杂症全靠它了!...
查看>>
提取series中的数值_Python中None和numpy.nan的区别
查看>>
hikariconfig mysql_HikariConfig配置解析
查看>>
mysql批量数据多次查询数据库_mysql数据库批量操作
查看>>
jquery 乱码 传参_jquery获取URL中参数解决中文乱码问题的两种方法
查看>>
JDBC_MySQL_jdbc连接mysql_MySQL
查看>>
新手学习python零基础_新手零基础学习Python第一步,搭建开发环境!
查看>>
mysql cte的好处_Mysql 8 重要新特性 - CTE 通用表表达式
查看>>
zcu106 固化_xilinx zcu106 vcu demo
查看>>
java 打印万年历_Java基础之打印万年历
查看>>
java ftpclient 代码_java后台代码ftpclient下载文件
查看>>
java mina 长连接_MINA实现TCP长连接(二)——服务端实现
查看>>
java数据库生成model_继承BaseModelGenerator 生成Model时添加数据库表字段 生成代码示例...
查看>>